一年一度的鐵人賽又到了!!今年...
今年沒有報名的打算 XD ... 來亂的
但想延續 2020 第十二屆鐵人賽的主題,Neo4j 看圖說故事,開始在這裡不定期發文分享
並針對一些我有興趣的主題,做更深入的探索與學習,不再是以鐵人賽一天一篇速讀文章為目標。
對於 Neo4j 圖形資料庫特性有興趣的朋友,可以先看看我之前的鐵人賽文章喔~
2020 鐵人賽 - Neo4j 看圖說故事
接下來我會把重心放在 Neo4j Graph Data Science,如果你對 GDS 也有興趣,可以看看之前兩篇鐵人賽文章當作參考
Neo4j Graph Data Science - 評估記憶體與建立子圖
Neo4j Graph Data Science - 演算法實作資料分析
與之前 GDS 文章的不同是,我會試著更完整且深入的介紹 GDS,嘗試更多的演算法與範例,並且專注在最新版的語法。另外,考量到文章的完整性,有些之前文章介紹過的內容,我還是會一併貼過來。
因收到網友留言說,之前鐵人賽的 GDS 文章,感覺省略不少基本的說明,例如語法結構,或是演算法詳細的參數設定等等,再加上自己也想針對 GDS 更深入的學習,索性就延續著鐵人賽主題,繼續在這裡耕耘了。
而 Neo4j 是排名第一的純圖形結構資料庫,比起以關聯式資料表模擬的圖資料庫,效能要好得多,在查詢複雜關聯的資料模型時也更得心應手與直覺,不用一直去思考:我要 Join 那些 TABLE,因為建立資料的過程,就已經建立好關聯性。相信在大型複雜關聯資料中探索資料的價值 (例如無限深度的人物關係圖),GDS 會是更好的選擇。
Neo4j 官方有為 GDS 準備了豐富的 Sandbox 環境 ,讓大家可以快速上手操作 GDS,這次我選擇了 For Data Scientists Beginner,雖說是 Beginner project,但已經足夠用來練習尋找中心點、群聚分析、節點相似度、最短路徑等實用的演算法。
現在的 Sandbox 版本,有多了一個貼心的設計,就是專案建立完成後,只要按下 Neo4j Desktop,且你本機上也有安裝 Neo4j Desktop,那麼就會自動將資料庫連線資訊與帳密直接帶入,省略自己複製貼上的麻煩。
透過瀏覽器或 Neo4j Desktop 開啟上述的 GDS 專案後,會直接跳出一段教學內容,這篇文章主要就是以這篇教學為參考。你也可以直接在 Neo4j Browser 輸入
:play https://guides.neo4j.com/airport-routes/index.html
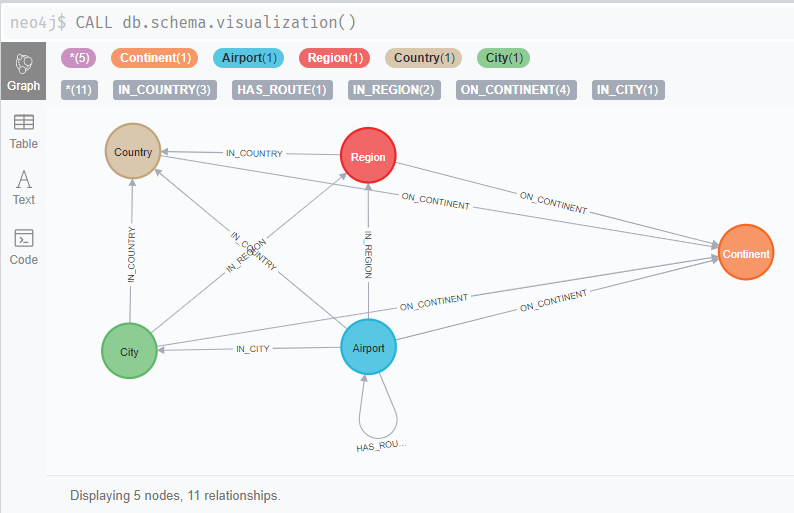
跟之前鐵人賽初體驗 Neo4j GDS 一樣,第一次接觸不熟悉的資料庫,我們最好先大略觀察一下 DB Schema
CALL db.schema.visualization()
這個圖我刻意整理過,可以很清楚看出,這是一個全球機場飛航的資料庫,可以很簡單理解為:
在執行 GDS 演算法之前,除了 DB Schema,我們還可以藉由 Cypher 語法對資料做更多的探索與調查,藉由統計資料,我們可以對資料的分布有一些概念。以下是官方範例。
一覽各大洲的機場總數
MATCH (c:Continent)
return c.name AS continent_name, SIZE((:Airport)-[:ON_CONTINENT]->(c)) AS num_airports
ORDER BY num_airports DESC
求得所有機場相關航線數的統計 (最少航線數、最多航線數、平均航線數、標準差)
MATCH (a:Airport)-[:HAS_ROUTE]->()
WITH a, count(*) AS num
RETURN min(num) AS min, max(num) AS max, avg(num) AS avg_routes, stdev(num) AS stdev
求得所有機場相關航線距離的統計 (最短航線距離、最長航線距離、平均航線距離、標準差)
MATCH (:Airport)-[r:HAS_ROUTE]->(:Airport)
RETURN min(r.distance) AS min, max(r.distance) AS max, avg(r.distance) AS avg_distance, stdev(r.distance) AS stdev
執行 GDS 演算法的第一步,就是要額外建立 projection graph,之前我的文章是翻譯成「子圖」,或你要直翻成「投影圖」都好,總之就是在記憶體中建立一個原本圖資料庫的「子集合」。
這個步驟很重要,是因為要加快演算法執行的效率與速度,所以預期只將有需要的圖和屬性放到記憶體做運算。
語法結構如下
CALL gds.graph.project(
graphName: String,
nodeProjection: String or List or Map,
relationshipProjection: String or List or Map,
configuration: Map // OPTIONAL
)
YIELD
graphName: String,
nodeProjection: Map,
nodeCount: Integer,
relationshipProjection: Map,
relationshipCount: Integer,
projectMillis: Integer,
createMillis: Integer
※ 之後的範例我都會省略 YIELD,因為這是 Neo4j Cypher 語法,跟 GDS 無直接相關,需要取得那些回傳的資料,全看需求而定。
※ GDS 舊版 (<=1.8) 的語法是 gds.graph.create,新版 (2.0+) 以後的語法是 gds.graph.project,之後我都會以新版語法為準。
以下是一個最簡單的範例,用所有機場和全部航線建立一個 projection
CALL gds.graph.project(
'routes',
'Airport',
'HAS_ROUTE'
)
我們也可以用多種節點和關聯來建立圖形
CALL gds.graph.project(
'routesWithCities',
['Airport', 'City'],
['HAS_ROUTE', 'IN_CITY']
)
需要注意的是,預設放到 projection graph 的只有節點和關係本身,至於它們包含的任何屬性資料,預設都不會存入記憶體中,所以如果我們預期執行的演算法需要用到特定屬性資料,就需要額外指定。
所以實際上建立 projection 的過程,對資料的操作與選擇可以相當的彈性,以下這個範例除了選定節點與關係,還指定了需要的屬性、預設值。甚至可以將原本的關聯轉向或改成無向性。
不過這範例只是為了呈現語法的結構給大家看,圖形本身不具特別意義。
CALL gds.graph.project(
'routesWithCities',
{
Airport: { properties: 'altitude' }, // 指定屬性
City: { properties: { runways: {defaultValue: 1} } } // 指定屬性,如果沒有該屬性,則給予預設值 1
},
{
HAS_ROUTE: { orientation: 'REVERSE', properties: 'distance' }, // 建立圖的過程將關係反向,並指定屬性
IN_CITY: { orientation: 'UNDIRECTED' } // 建立圖的過程將關係改為無方向性
},
{
nodeProperties: 'id', // 為所有節點指定屬性
relationshipProperties: 'distance' // 為所有關聯指定屬性
}
)
※ 目前 GDS 並不支援字串屬性,而 id 屬性在這個資料庫中是字串,不是數字,所以實際上這個範例執行會有錯誤訊息。
Graph Catalog 是儲存 projection graph 的一個概念,儲存在這裡的圖形,會一直存放在直到 Neo4j 伺服器關掉或重新啟動,或是被使用者手動移除。
另外要注意的是,每個圖形的建立是綁定 user 的,每個使用者只能存取用自己帳號建立的圖形。
上個段落我用的語法是屬於 Native Projection,而 Cypher Projection 顧名思義,就是讓使用者用 Cypher 語法來更精確地自訂 projection graph,如下範例
CALL gds.graph.project.cypher(
'routesWithCypher',
'MATCH (a:Airport) RETURN id(a) AS id',
'MATCH (a:Airport)-[r:HAS_ROUTE]->(b:Airport) RETURN id(a) AS source, id(b) AS target')
什麼時候用 Native projection,什麼時候用 Cypher projection 呢?兩者的差異在於效能與彈性,Cypher projection 執行比較慢,但可以很明確的限制小範圍資料來測試演算法,才不會每次 DEBUG 都要等上一段咖啡時間,適合用在開發環境;Native projection 執行效率比較好,可以用在正式產品環境。
這邊直接列出指令讓大家回顧,過去鐵人賽文章已介紹過,不再重述
CALL gds.graph.list()
CALL gds.graph.list('routes')
call gds.graph.drop('routes')
有了 projection graph 之後,就可以開始準備演算法了,語法結構如下
CALL gds[.<tier>].<algorithm>.<execution-mode>[.<estimate>](
graphName: String,
configuration: Map
)
新舊版有些微差異的是 estimate 評估記憶體用量的語法,須要明確的指定第二參數,即使預期全部使用預設值,以 PageRank 演算法為例
CALL gds.pageRank.stream.estimate('routes', {})
Page Rank 是 Google 早期對網頁排名所採用的演算法,其原理是,一個網頁被其他網頁參考並連結的次數愈多,意義上相當於被其他頁面「投票」,那麼該頁面的重要性就會愈高;而來源網頁的重要性愈高,被投票的網頁重要性也會增加。
雖然是評估網頁重要性的算法,但也能用來評估圖形資料庫中節點的相對重要性。
既然知道 PageRank 演算法的重要依據是外部關係的數量,我們可以先以這個概念,直接用 Cypher 找出對外關係數的排名如下
MATCH (a:Airport)
WITH a, SIZE((a)-[:HAS_ROUTE]-(:Airport)) AS degree
RETURN a.city AS city, a.iata AS airport_code, degree
ORDER BY degree DESC
接著比對 PageRank 演算法的執行結果,可以發現兩種排名結果大致上吻合,只是 PageRank 演算法不只考慮關係數,還要考慮建立關係的對向其重要程度,是迭代型的演算法。迭代次數愈多,演算法跑得愈久,但是結果會更精確。
CALL gds.pageRank.stream('routes')
YIELD nodeId, score
WITH gds.util.asNode(nodeId) as node, score
RETURN node.iata AS iata, node.descr AS description, score
ORDER BY score DESC, iata ASC
YIELD 後面都是屬於應用情境,我們回來看 GDS 語法本身,以下是自定義 PageRank 演算法細節,試圖求出更精確的結果,並將 PR 寫回原圖形資料庫
CALL gds.pageRank.write('routes',
{
writeProperty: 'pagerank',
maxIterations: 30, // 迭代次數改為 30,預設為 20
tolerance: 0.00000008 // 兩次迭代的結果差距如果小於這個數值,則視為足夠穩定,不需要繼續迭代下去
}
)
每種演算法可以設定的 Configuration 都不一樣,這部分須自行參考官方 GDS Algorithms 文件
之前的鐵人賽文章,群聚分析用的是 Label Propagation 演算法,這次官方範例選用的是 Louvain,也是一個迭代型演算法。一開始會假設每一個節點都是一個群,並評估與每個相鄰的群合併後得到的 modularity 數值,找到最大值之後,進行合併。然後再回到前一步驟,持續與相鄰的「群」評估合併後的 modularity,尋找最大值合併。如此不斷迭代下去,最後 modularity 數值會漸漸趨於穩定,變化愈來愈小,就完成了群聚。
如果你需要更詳細的解釋,我找到了一位網友 Samir Liu 的 blog,感謝他對 Louvain 算法有著圖文並茂的介紹,也有公式與細節,讓我可以更容易理解學習。
以下是官方的範例,經過 Louvain 算法後,將集群 id、機場數量、所在城市列出,可以發現最後分群的結果,大致上是以洲/大陸的地理位置來區分。
CALL gds.louvain.stream('routes')
YIELD nodeId, communityId
RETURN
communityId,
SIZE(COLLECT(gds.util.asNode(nodeId).iata)) AS number_of_airports,
COLLECT(gds.util.asNode(nodeId).city) AS city
ORDER BY number_of_airports DESC, communityId;

相似性演算法很適合用來做推薦系統,例如使用者瀏覽了商品 A,那麼系統可以用這類演算法來找出與商品 A 相似度最高的幾個商品,對使用者呈現為「您可能也會想看看 ...」之類的功能,增加使用者找到預期商品的機率,進而刺激下單購買。 Neo4j GDS 提供了 Node similarity 演算法來評估節點與節點之間的相似度,其運用了 Jaccard similarity 來計算相似度。
Jaccard similarity 的概念很簡單,就是交集/聯集,當交集完全等於聯集的時候,兩者就是完全相似的物品;反之如果兩者沒有任何交集,就是完全不相關的物品。所以 Jaccard similarity score 是介於 0 與 1 之間的數值。至於取得交集與聯集的作法,是可以自定義的。
GDS Node similarity 則是評估兩個節點之間共同的關聯節點,關連節點數愈多,兩者相似度愈高。
但是要特別注意的是,這個演算法的時間複雜度是 ,所以可能需要對計算深度做一點限制來節省運算時間。
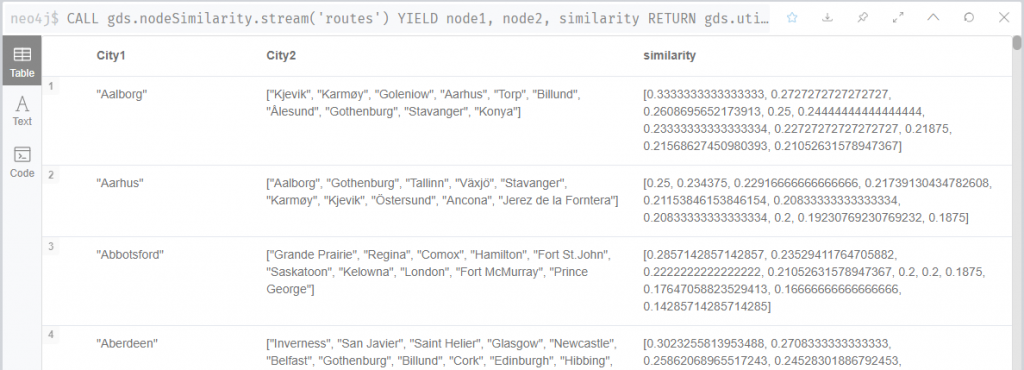
以下是沒有特別限制的使用 Node similarity,計算出每個節點的相似節點,以及相似度係數,可以發現每個節點預設只會找出相似度最高的 10 個節點。
CALL gds.nodeSimilarity.stream('routes')
YIELD node1, node2, similarity
RETURN
gds.util.asNode(node1).city AS City1,
COLLECT(gds.util.asNode(node2).city) AS City2,
COLLECT(similarity) AS similarity
ORDER BY City1
如前所述,為了節省運算時間,我們可以有許多限制搜索深度的作法如下
CALL gds.nodeSimilarity.stream(
'routes',
{
topK: 3, // 每個節點只找出相似度最高的 3 個節點,預設是 10
topN: 100 // 針對整個圖形,計算全部相似節點的數量限制,100 表示只找出相似度最高的 100 個節點。預設是 0 表示沒有限制,
degreeCutoff: 50, // 節點的最低深度要求,在這個案例中就是機場的飛航關聯數總和若小於 50 就會被忽略不計
similarityCutoff: 0.8 // 最低相似度要求,小於這個相似度就忽略不計
}
)
這邊的參數有些有趣的組合,大家可以動手試試看
最後來看看 GDS 提供的路徑搜尋演算法 Dijkstra,用來尋找兩點間最短路徑。關於 Dijkstra 演算法的理論細節,我直接找到了同樣是第十二屆鐵人賽 IT邦友小菜的文章給大家參考 戴克斯特拉演算法求最短路徑 ,而為此我們也需要將原本機場之間航線距離也放到記憶體圖形中。
CALL gds.graph.project(
'routes-weighted',
'Airport',
'HAS_ROUTE',
{
relationshipProperties: 'distance'
}
)
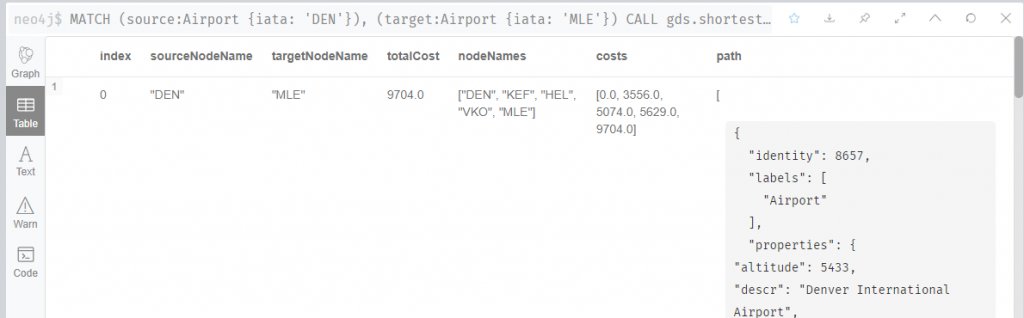
以下是 GDS Dijkstra 演算法實例操作,可以看到執行結果包含了最短距離中間經過的所有節點,以及累計的里程數
MATCH (source:Airport {iata: 'DEN'}), (target:Airport {iata: 'MLE'})
CALL gds.shortestPath.dijkstra.stream('routes-weighted', {
sourceNode: source,
targetNode: target,
relationshipWeightProperty: 'distance'
})
YIELD index, sourceNode, targetNode, totalCost, nodeIds, costs, path
RETURN
index,
gds.util.asNode(sourceNode).iata AS sourceNodeName,
gds.util.asNode(targetNode).iata AS targetNodeName,
totalCost,
[nodeId IN nodeIds | gds.util.asNode(nodeId).iata] AS nodeNames,
costs,
nodes(path) as path
ORDER BY index
以上就是我作為重新入門 Neo4j GDS 的完整介紹,搭配官方 Sandbox 的範例與順序,把之前沒講到的基本觀念與操作都盡量交代到,也分享給你一起學習。
之後我仍會暫時聚焦在 GDS,並嘗試更多的演算法與應用情境,期望您能繼續支持我的分享~
另外,如果你不是個人使用,而是企業經營,想考慮導入圖形資料庫,我覺得可以參考 Neo4j 官方代理商日新科技提供的服務,包含了顧問諮詢、教育訓練、POC服務、客製化服務、等等;或是Neo4j實績導入暨應用場景案例分享。
Neo4j GDS Document
Neo4j GDS Entrypoint
Neo4j 超越所有圖型資料庫,突破兆級以上資料量關係圖!
Community detection 社區發現 (Louvain)
戴克斯特拉演算法求最短路徑
 蛋踢球
蛋踢球
